


Symbiotic Interfaces For Wearable Face Recognition
Bradley A. Singletary and Thad E. Starner
College Of Computing, Georgia Institute of Technology, Atlanta, GA 30332
{bas,thad}@cc.gatech.edu
Abstract
We introduce a wearable face detection method that exploits
constraints in face scale and orientation imposed by the proximity of
participants in near social interactions. Using this method we
describe a wearable system that perceives ``social engagement,'' i.e.,
when the wearer begins to interact with other individuals. One
possible application is improving the interfaces of portable consumer
electronics, such as cellular phones, to avoid interrupting the user
during face-to-face interactions. Our experimental system proved
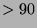 % accurate when tested on wearable video data captured at a
professional conference. Over three hundred individuals were captured,
and the data was separated into independent training and test sets. A
goal is to incorporate user interface in mobile machine recognition
systems to improve performance. The user may provide real-time
feedback to the system or may subtly cue the system through typical
daily activities, such as turning to face a speaker, as to when
conditions for recognition are favorable.
In casual social interaction, it is easy to forget the names and
identities of those we meet. The consequences can range from the need
to be reintroduced to the ``opportunity cost'' of a missed business
contact. At organized social gatherings, such as professional
conferences, name tags are used to assist attendees'
memories. Recently, electronic name tags have been used to transfer,
index, and remember contact information for attendees
[Borovoy et al., 1996]. For everyday situations where convention-style
name tags are inappropriate, a wearable face recognition system may
provide face-name associations and aid in recall of prior interactions
with the person standing in front of the wearable user
[Farringdon and Oni, 2000,Starner et al., 1997,Brzezowski et al., 1996,Iordanoglou et al., 2000].
% accurate when tested on wearable video data captured at a
professional conference. Over three hundred individuals were captured,
and the data was separated into independent training and test sets. A
goal is to incorporate user interface in mobile machine recognition
systems to improve performance. The user may provide real-time
feedback to the system or may subtly cue the system through typical
daily activities, such as turning to face a speaker, as to when
conditions for recognition are favorable.
In casual social interaction, it is easy to forget the names and
identities of those we meet. The consequences can range from the need
to be reintroduced to the ``opportunity cost'' of a missed business
contact. At organized social gatherings, such as professional
conferences, name tags are used to assist attendees'
memories. Recently, electronic name tags have been used to transfer,
index, and remember contact information for attendees
[Borovoy et al., 1996]. For everyday situations where convention-style
name tags are inappropriate, a wearable face recognition system may
provide face-name associations and aid in recall of prior interactions
with the person standing in front of the wearable user
[Farringdon and Oni, 2000,Starner et al., 1997,Brzezowski et al., 1996,Iordanoglou et al., 2000].
Currently, such systems are computationally complex and create a drain
on the limited battery resources of a wearable computer. However,
when a conversant is socially engaged with the user, a weak constraint
may be exploited for face recognition. Specifically, search over
scale and orientation may be limited to that typical of the near
social interaction distances. Thus, we desire a lightweight system
that can detect social engagement and indicate that face recognition
is appropriate. Wearable computers must balance their interfaces
against human burden. For example, if the wearable computer interrupts
its user during a social interaction (e.g. to alert him to a wireless
telephone call), the conversation may be disrupted by the intrusion.
Detection of social engagement allows for blocking or delaying
interruptions appropriately during a conversation.
To visually identify social engagement, we wish to use features endemic of
that social process. Eye fixation, patterns of change in head orientation,
social conversational distance, and change in visual spatial content may be
relevant [Selker et al., 2001,Reeves, 1993,Hall, 1963].
For now, as we are uncertain which
features are appropriate for recognition, we induce a set of behaviors
to assist the computer. Specifically, the
wearer aligns x's on an head-up display with the eyes of the subject
to be recognized. As we learn more about the applicability of our
method from our sample data set, we will extend our recognition
algorithms to include non-induced behaviors.
While there are many face detection, localization, and recognition
algorithms in the literature that were considered as potential
solutions to our problem
[Feraud et al., 2001,Rowley et al., 1998,Schneiderman and Kanade, 2000,Leung et al., 1995], our
task is to recognize social engagement in context of human behavior and the
environment. Face presence may be one of the most important features, but
it is not the only feature useful for segmenting engagement. In
examination of 10 standard face databases (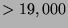 images), we found
that background contents had little variation. By comparison, scenes
obtained from a body-worn camera in everyday life contained highly
varied scene backgrounds. In addition to the presence of the face, we
would like to exploit the movement of the face with respect to the
wearer's camera. Given prior work on the visual modeling of human
interaction
[Oliver et al., 1998,Ivanov et al., 1999,Moore, 2000,Starner and Pentland, 1998,Starner et al., 1998,Nefian, 1999],
we chose hidden Markov Models(HMMs) as the basis of our recognition
system.
images), we found
that background contents had little variation. By comparison, scenes
obtained from a body-worn camera in everyday life contained highly
varied scene backgrounds. In addition to the presence of the face, we
would like to exploit the movement of the face with respect to the
wearer's camera. Given prior work on the visual modeling of human
interaction
[Oliver et al., 1998,Ivanov et al., 1999,Moore, 2000,Starner and Pentland, 1998,Starner et al., 1998,Nefian, 1999],
we chose hidden Markov Models(HMMs) as the basis of our recognition
system.
We collected video data from a wearable camera at an academic
conference, a setting representative of social interaction of the
wearer and new acquaintances. The capture environment was highly
unconstrained and ranged from direct sunlight to darkened conference
hall. Approximately 300 subjects were captured one or more times over
10 hours. The images in Figure
1 are locations in the video annotated
by the wearer to be faces.
Figure 1:
Representative data set
|
Figure 2:
Marks for user alignment and face capture apparatus
|
Our prototype wearable camera video capture system (see Figure
2) consists of: a color
camera, an infrared(IR) sensitive black and white camera, a low-power
IR illuminator, two digital video(DV) recorder decks, one video
character generator, one audio tone generator, a Sony Glasstron
head-up display, and four lithium ion
camcorder batteries. Output from the cameras is recorded to DV. The HMD
augments the user's view with two 'x' characters. The 'x' characters
represent known locations for a subject's eyes to appear in the video feed.
To capture face data, the wearer of the vest approaches a subject and aligns
the person's eyes with the two 'x' characters. The video is then annotated by
the user pressing a button which injects an audio tone into the DV stream
at the location of the face data.
The video data was automatically extracted into 2 second partitions
and divided into two classes using frames annotated by the wearer. The
two classes were ``engagement'' and ``other''. As may be expected, the
number of engagement gestures per hour of interaction was much smaller than
the number of examples in the garbage class. Since the wearer lined up two x's
with the eyes of a viewed subject, the presence of a face could safely be
guaranteed to be framed by a 360x360 subregion of the 720x480 DV frame at the
annotated locations in the video. Faces present at engagement were large with
respect to the subregion. We first convert to greyscale, deinterlace, and
correct non-squareness of the image pixels in the subregion. We downsampled
the preprocessed region of video to 22x22 images using the linear heat
equations to gaussian diffuse each level of the pyramid before
subsampling to the next level. Each resulting frame/element in a
2-second gesture example is one 22x22 greyscale subregion (484 element
vector).
Figure 3:
Other and Engagement classes
|
We model the face class by a 3 state Left-Right HMM as shown in Figure
3. The other class was much more complex to model
and required a 6 state ergodic model to capture the interplay of
garbage types of scenes as shown in Figure 3. We
plot the mean values of the state output probabilities. The presence
of a face seems important for acceptance by the face model. The first
state contains a rough face-like blob and is followed by a confused
state that likely represents the alignment portion of our gesture.
The final state is clearly face-like, with much sharper features than
the first state and would be consistent with conversational
engagement. Looking at the other class model, we see images that
look like horizons and very dark or light scenes. The complexity of
the model allowed wider variations in scene without loss in accuracy.
Finally, background models could certainly be improved by building location
aware models of environment specific features.
represented.
Table 1:
Accuracy and confusion for engagement detection
| experiment |
training set |
independent |
|
| |
|
test |
|
| 22x22 video stream |
89.71% |
90.10% |
|
| train |
engagement |
other |
|
| confusion, N=843 |
|
|
|
| engagement |
82.1%(128) |
17.9%(28) |
|
| other |
8.6%(63) |
91.3%(665) |
|
| test |
engagement |
other |
|
| confusion, N=411 |
|
|
|
| engagement |
83.3%(50) |
16.7%(10) |
|
| other |
8.7%(30) |
91.3%(314) |
|
Accuracy results and confusion matrices are shown in Table
1. How effective is leveraging detection of social
engagement as compared to continuously running face recognition? If we were to
construct a wearable face recognition system using our engagement
detector, we would combine the social engagement detector with a
scale-tuned localizer and a face recognizer. The cost of the social
engagement detector must be sufficiently small to allow for the larger
costs of localization and recognition. This is described by the inequality
where 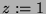 is the total resources available,
is the total resources available, 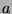 is the fixed cost of running engagement detection
once in sec/frames,
is the fixed cost of running engagement detection
once in sec/frames, 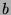 is the fixed cost of running localization and
recognition methods once in sec/frames, and
is the fixed cost of running localization and
recognition methods once in sec/frames, and 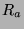 and
and 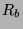 are the rate
at which we can supply the respective detectors with frames in
frames/sec, respectively. However, has a maximum value determined by either the
fraction of false positives
are the rate
at which we can supply the respective detectors with frames in
frames/sec, respectively. However, has a maximum value determined by either the
fraction of false positives 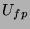 multiplied by the maximum input
frame rate or the rate at which the user wants to be advised of the
identity of a conversant
multiplied by the maximum input
frame rate or the rate at which the user wants to be advised of the
identity of a conversant 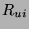 . Thus,
Note that fixating the camera on a true face could cause up to
frames per second to be delivered to the face recognizer. However, we
assume that the user does not want to be updated this quickly or
repeatedly (i.e.
. Thus,
Note that fixating the camera on a true face could cause up to
frames per second to be delivered to the face recognizer. However, we
assume that the user does not want to be updated this quickly or
repeatedly (i.e.
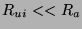 ). We also assume that
our rate of false positives will almost always be greater than the
rate the user wants to be informed, leaving us with
For comparison purposes, we will assume that the average time per
frame of processing for the localization and recognition process can
be represented by some multiple of the average detection time (i.e.
). We also assume that
our rate of false positives will almost always be greater than the
rate the user wants to be informed, leaving us with
For comparison purposes, we will assume that the average time per
frame of processing for the localization and recognition process can
be represented by some multiple of the average detection time (i.e.
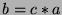 ). Thus, for a given multiplier
). Thus, for a given multiplier 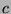 , we can determine the
maximum rate of false positives allowable by the face detection process.
Note that if
, we can determine the
maximum rate of false positives allowable by the face detection process.
Note that if 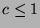 , then the localization and recognition process
runs faster than the face detection process. This situation would
imply that performing face detection separately from face localization
and recognition would not save processing time (i.e. localization and
recognition should run continually - again, if real-time face
recognition is the primary goal).Given a false positive rate ,
we solve the equation to determine the maximum allowable time for the
localization and recognition process as compared to the detection
process.Thus, we have a set of heuristics for determining when the
separation of face detection and face localization and recognition is
profitable.
Applying the metric from the previous section to our experimental
results, we let
, then the localization and recognition process
runs faster than the face detection process. This situation would
imply that performing face detection separately from face localization
and recognition would not save processing time (i.e. localization and
recognition should run continually - again, if real-time face
recognition is the primary goal).Given a false positive rate ,
we solve the equation to determine the maximum allowable time for the
localization and recognition process as compared to the detection
process.Thus, we have a set of heuristics for determining when the
separation of face detection and face localization and recognition is
profitable.
Applying the metric from the previous section to our experimental
results, we let
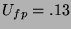 ,
, 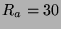 ,
,
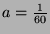 and solving
for we get
and solving
for we get 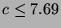 . Thus any recognition method used may be up
to 7.69 times slower than the engagement detection method and will
have a limiting frame rate of about four frames per second. Given
that our detection algorithm runs at 30fps, and our knowledge that
principal component analysis based face recognition and alignment can
run faster than roughly four times a second, we feel that engagement
detection can be a successful foundation for wearable face
recognition. Post-filtering outputs of detection may help
eliminate false positives before recognition
[Feraud et al., 2001]. Due to the face-like appearance of the final
state of the HMM, it is likely that the output of our method could
provide a reasonable first estimate of location to fine grain
localization. Other cues including detection of head stillness, eye
fixation, and conversational gestures like ``hello, my name is ...''
will likely reduce false positives[Reeves, 1993,Selker et al., 2001].
. Thus any recognition method used may be up
to 7.69 times slower than the engagement detection method and will
have a limiting frame rate of about four frames per second. Given
that our detection algorithm runs at 30fps, and our knowledge that
principal component analysis based face recognition and alignment can
run faster than roughly four times a second, we feel that engagement
detection can be a successful foundation for wearable face
recognition. Post-filtering outputs of detection may help
eliminate false positives before recognition
[Feraud et al., 2001]. Due to the face-like appearance of the final
state of the HMM, it is likely that the output of our method could
provide a reasonable first estimate of location to fine grain
localization. Other cues including detection of head stillness, eye
fixation, and conversational gestures like ``hello, my name is ...''
will likely reduce false positives[Reeves, 1993,Selker et al., 2001].
We described a platform built to capture video from a wearable user's
perspective and detailed a method for efficient engagement detection.
We tested our system in a representative scenario and devised a metric
for evaluating it's efficacy as part of a face recognition scheme. In
doing so, we demonstrated how the design of user interfaces that are aware
of social contexts and constraints can positively affect recognition
systems on the body. Finally, we have described how the detection of
social engagement may be used, in its own right, to improve
interfaces on portable consumer devices.
- Borovoy et al., 1996
-
Borovoy, R., McDonald, M., Martin, F., and Resnick, M. (1996).
Things that blink: A computationally augmented name tag.
IBM Systems Journal, 35(3).
- Brzezowski et al., 1996
-
Brzezowski, S., Dunn, C. M., and Vetter, M. (1996).
Integrated portable system for suspect identification and tracking.
In DePersia, A. T., Yeager, S., and Ortiz, S., editors, SPIE:Surveillance and Assessment Technologies for Law Enforcement.
- Farringdon and Oni, 2000
-
Farringdon, J. and Oni, V. (2000).
Visually augmented memory.
In Fourth International Symposium on Wearable Computers,
Atlanta, GA. IEEE.
- Feraud et al., 2001
-
Feraud, R., Bernier, O. J., Viallet, J.-E., and Collobert, M. (2001).
A fast and accurate face detector based on neural networks.
Pattern Analysis and Machine Intelligence, 23(1):42-53.
- Hall, 1963
-
Hall, E. T. (1963).
The Silent Language.
Doubleday.
- Iordanoglou et al., 2000
-
Iordanoglou, C., Jonsson, K., Kittler, J., and Matas, J. (2000).
Wearable face recognition aid.
In Interntional Conference on Acoustics, Speech, and Signal
Processing. IEEE.
- Ivanov et al., 1999
-
Ivanov, Y., Stauffer, C., Bobic, A., and Grimson, E. (1999).
Video surveillance of interactions.
In CVPR Workshop on Visual Surveillance, Fort Collins, CO.
IEEE.
- Leung et al., 1995
-
Leung, T. K., Burl, M. C., and Perona, P. (1995).
Finding faces in cluttered scenes using random labelled graph
matching.
In 5th Inter. Conference on Computer Vision.
- Moore, 2000
-
Moore, D. J. (2000).
Vision-based recognition of actions using context.
PhD thesis, Georgia Institute of Technology, Atlanta, GA.
- Nefian, 1999
-
Nefian, A. (1999).
A hidden Markov model-based approach for face detection and
recognition.
PhD thesis, Georgia Institute of Technology, Atlanta, GA.
- Oliver et al., 1998
-
Oliver, N., Rosario, B., and Pentland, A. (1998).
Statistical modeling of human interactions.
In CVPR Workshop on Interpretation of Visual Motion, pages
39-46, Santa Barbara, CA. IEEE.
- Reeves, 1993
-
Reeves, J. (1993).
The face of interest.
Motivation and Emotion, 17(4).
- Rowley et al., 1998
-
Rowley, H. A., Baluja, S., and Kanade, T. (1998).
Neural network-based face detection.
IEEE Transactions on Pattern Analysis and Machine Intelligence,
20(1).
- Schneiderman and Kanade, 2000
-
Schneiderman, H. and Kanade, T. (2000).
A statistical model for 3d object detection applied to faces and
cars.
In Computer Vision and Pattern Recognition. IEEE.
- Selker et al., 2001
-
Selker, T., Lockerd, A., and Martinez, J. (2001).
Eye-r, a glasses-mounted eye motion detection interface.
In to appear CHI2001. ACM.
- Starner et al., 1997
-
Starner, T., Mann, S., Rhodes, B., Levine, J., Healey, J., Kirsch, D., Picard,
R. W., and Pentland, A. (1997).
Augmented reality through wearable computing.
Presence special issue on Augmented Reality.
- Starner and Pentland, 1998
-
Starner, T. and Pentland, A. (1998).
Real-time American sign language recognition using desktop and
wearable computer based video.
Pattern Analysis and Machine Intelligence.
- Starner et al., 1998
-
Starner, T., Schiele, B., and Pentland, A. (1998).
Visual contextual awareness in wearable computing.
In International Symposium on Wearable Computing.
Symbiotic Interfaces For Wearable Face Recognition
This document was generated using the
LaTeX2HTML translator Version 2K.1beta (1.49)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 paper.tex
The translation was initiated by Bradley A. Singletary on 2001-09-18
Bradley A. Singletary
2001-09-18
![\includegraphics[width=16cm, angle=0,keepaspectratio]{images/dataexample.eps}](img3.gif)
![\includegraphics[height=3.9cm,angle=0]{images/threeimgs.eps}](img4.gif)
![\includegraphics[width=8cm, angle=0,keepaspectratio]{images/bothhmms2.eps}](img5.gif)